Contents
Articles
2026
- What the last decade of Android Enterprise DPC migration could have been
- Introducing DeltaWatch: web change detection
- Android Enterprise lands on Android XR
- How MIKA works: building an AI assistant for bayton.org
- Bayton.org goes AI-first: meet MIKA
- TCL Note A1 NXTPAPER hands-on
- What's new in the 2026 Android Security Paper?
- MDM is dead. Long live ACE?
- Introducing AMAPI Commander: converse with your Android estate
- MANAGED INFO is going licence-free
2025
- Google Play Protect is now the custom DPC gatekeeper, and everyone is a threat by default
- 12 deliveries of AE-mas (What shipped in Android Enterprise in 2025)
- The 12 AE requests of Christmas (2025 Edition)
- RCS Archival and you: clearing up the misconceptions
- Device Trust from Android Enterprise: What it is and how it works (hands-on)
- Android developer verification: what this means for consumers and enterprise
- AMAPI finally supports direct APK installation, this is how it works
- The Android Management API doesn't support pulling managed properties (config) from app tracks. Here's how to work around it
- Hands-on with CVE-2025-22442, a work profile sideloading vulnerability affecting most Android devices today
- AAB support for private apps in the managed Google Play iFrame is coming, take a first look here
- What's new (so far) for enterprise in Android 16
2024
- Android 15: What's new for enterprise?
- How Goto's acquisition of Miradore is eroding a once-promising MDM solution
- Google Play Protect no longer sends sideloaded applications for scanning on enterprise-managed devices
- Mobile Pros is moving to Discord
- Avoid another CrowdStrike takedown: Two approaches to replacing Windows
- Introducing MANAGED SETTINGS
- I'm joining NinjaOne
- Samsung announces Knox SDK restrictions for Android 15
- What's new (so far) for enterprise in Android 15
- Google quietly introduces new quotas for unvalidated AMAPI use
- What is Play Auto Install (PAI) in Android and how does it work?
- AMAPI publicly adds support for DPC migration
- How do Android devices become certified?
2023
- Mute @channel & @here notifications in Slack
- A guide to raising better support requests
- Ask Jason: How should we manage security and/or OS updates for our devices?
- Pixel 8 series launches with 7 years of software support
- Android's work profile behaviour has been reverted in 14 beta 5.3
- Fairphone raises the bar with commitment to Android updates
- Product files: The DoorDash T8
- Android's work profile gets a major upgrade in 14
- Google's inactive account policy may not impact Android Enterprise customers
- Product files: Alternative form factors and power solutions
- What's new in Android 14 for enterprise
- Introducing Micro Mobility
- Android Enterprise: A refresher
2022
- What I'd like to see from Android Enterprise in 2023
- Thoughts on Android 12's password complexity changes
- Google Play target API requirements & impact on enterprise applications
- Sunsetting Discuss comment platform
- Google publishes differences between Android and Android Go
- Android Go & EMM support
- Relaunching bayton.org
- AER dropped the 3/5 year update mandate with Android 11, where are we now?
- I made a bet with Google (and lost)
2020
- Product files: Building Android devices
- Google announce big changes to zero-touch
- VMware announces end of support for Device Admin
- Google launch the Android Enterprise Help Community
- Watch: An Android Enterprise discussion with Hypergate
- Listen again: BM podcast #144 - Jason Bayton & Russ Mohr talk Android!
- Google's Android Management API will soon support COPE
- Android Enterprise in 11: Google reduces visibility and control with COPE to bolster privacy.
- The decade that redefined Android in the enterprise
2019
- Why Intune doesn't support Android Enterprise COPE
- VMware WS1 UEM 1908 supports Android Enterprise enrolments on closed networks and AOSP devices
- The Bayton 2019 Android Enterprise experience survey
- Android Enterprise Partner Summit 2019 highlights
- The Huawei ban and Enterprise: what now?
- Dabbling with Android Enterprise in Q beta 3
- Why I moved from Google WiFi to Netgear Orbi
- I'm joining Social Mobile as Director of Android Innovation
- Android Enterprise in Q/10: features and clarity on DA deprecation
- MWC 2019: Mid-range devices excel, 5G everything, form-factors galore and Android Enterprise
- UEM tools managing Android-powered cars
- Joining the Android Enterprise Experts community
- February was an interesting month for OEMConfig
- Google launch Android Enterprise Recommended for Managed Service Providers
- Migrating from Windows 10 Mobile? Here's why you should consider Android
- AER expands: Android Enterprise Recommended for EMMs
- What I'd like to see from Android Enterprise in 2019
2018
- My top Android apps in 2018
- Year in review: 2018
- MobileIron Cloud R58 supports Android Enterprise fully managed devices with work profiles
- Hands on with the Huawei Mate 20 Pro
- Workspace ONE UEM 1810 introduces support for Android Enterprise fully managed devices with work profiles
- G Suite no longer prevents Android data leakage by default
- Live: Huawei Mate series launch
- How to sideload the Digital Wellbeing beta on Pie
- How to manually update the Nokia 7 Plus to Android Pie
- Hands on with the BQ Aquaris X2 Pro
- Hands on with Sony OEMConfig
- The state of Android Enterprise in 2018
- BYOD & Privacy: Don’t settle for legacy Android management in 2018
- Connecting two Synologies via SSH using public and private key authentication
- How to update Rsync on Mac OS Mojave and High Sierra
- Intune gains support for Android Enterprise COSU deployments
- Android Enterprise Recommended: HMD Global launch the Nokia 3.1 and Nokia 5.1
- Android Enterprise Partner Summit 2018 highlights
- Live: MobileIron LIVE! 2018
- Android Enterprise first: AirWatch 9.4 lands with a new name and focus
- Live: Android Enterprise Partner Summit 2018
- Samsung, Oreo and an inconsistent Android Enterprise UX
- MobileIron launch Android Enterprise work profiles on fully managed devices
- Android P demonstrates Google's focus on the enterprise
- An introduction to managed Google Play
- MWC 2018: Android One, Oreo Go, Android Enterprise Recommended & Android Enterprise
- Enterprise ready: Google launch Android Enterprise Recommended
2017
- Year in review: 2017
- Google is deprecating device admin in favour of Android Enterprise
- Hands on with the Sony Xperia XZ1 Compact
- Moto C Plus giveaway
- The state of Android Enterprise in 2017
- Samsung launched a Note 8 for enterprise
- MobileIron officially supports Android Enterprise QR code provisioning
- Android zero-touch enrolment has landed
- MobileIron unofficially supports QR provisioning for Android Enterprise work-managed devices, this is how I found it
- Hands on with the Nokia 3
- Experimenting with clustering and data replication in Nextcloud with MariaDB Galera and SyncThing
- Introducing documentation on bayton.org
- Goodbye Alexa, Hey Google: Hands on with the Google Home
- Restricting access to Exchange ActiveSync
- What is Mobile Device Management?
- 8 tips for a successful EMM deployment
- Long-term update: the fitlet-RM, a fanless industrial mini PC by Compulab
- First look: the FreedomPop V7
- Vault7 and the CIA: This is why we need EMM
- What is Android Enterprise (Android for Work) and why is it used?
- Introducing night mode on bayton.org
- What is iOS Supervision and why is it used?
- Hands on with the Galaxy TabPro S
- Introducing Nextcloud demo servers
- Part 4 - Project Obsidian: Obsidian is dead, long live Obsidian
2016
- My top Android apps 2016
- Hands on with the Linx 12V64
- Wandera review 2016: 2 years on
- Deploying MobileIron 9.1+ on KVM
- Hands on with the Nextcloud Box
- How a promoted tweet landed me on Finnish national news
- Using RWG Mobile for simple, cross-device centralised voicemail
- Part 3 – Project Obsidian: A change, data migration day 1 and build day 2
- Hands on: fitlet-RM, a fanless industrial mini PC by Compulab
- Part 2 - Project Obsidian: Build day 1
- Part 1 - Project Obsidian: Objectives & parts list
- Part 0 - Project Obsidian: Low power NAS & container server
- 5 Android apps improving my Chromebook experience
- First look: Android apps on ChromeOS
- Competition: Win 3 months of free VPS/Container hosting - Closed!
- ElasticHosts review
- ElasticHosts: Cloud Storage vs Folders, what's the difference?
- Adding bash completion to LXD
- Android N: First look & hands-on
- Springs.io - Container hosting at container prices
- Apple vs the FBI: This is why we need MDM
- Miradore Online MDM: Expanding management with subscriptions
- Lenovo Yoga 300 (11IBY) hard drive upgrade
- I bought a Lenovo Yoga 300, this is why I'm sending it back
- Restricting access to Exchange ActiveSync
- Switching to HTTPS on WordPress
2015
2014
- Is CYOD the answer to the BYOD headache?
- BYOD Management: Yes, we can wipe your phone
- A fortnight with Android Wear: LG G Watch review
- First look: Miradore Online free MDM
- Hands on: A weekend with Google Glass
- A month with Wandera Mobile Gateway
- Final thoughts: Dell Venue Pro 11 (Atom)
- Thoughts on BYOD
- Will 2014 bring better battery life?
- My year in review: Bayton.org
- The best purchase I've ever made? A Moto G for my father
2013
2012
- My Top Android Apps 12/12
- The Nexus 7 saga: Resolved
- Recycling Caps Lock into something useful - Ubuntu (12.04)
- The Nexus 7 saga continues
- From Wows to Woes: Why I won't be recommending a Nexus7 any time soon.
- Nexus7: What you need to know
- Why I disabled dlvr.it links on Facebook
- HTC Sense: Changing the lockscreen icons from within ADW
2011
- Push your Google+ posts to Twitter and Facebook
- Using multiple accounts with Google.
- The "Wn-R48" (Windows on the Cr-48)
- Want a Google+ invite?
- Publishing to external sources from Google+
- Dell Streak review. The Phone/Tablet Hybrid
- BlueInput: The Bluetooth HID driver Google forgot to include
- Pushing Buzz to Twitter with dlvr.it
- Managing your social outreach with dlvr.it
- When Awe met Some. The Cr-48 and Gnome3.
- Living with Google's Cr-48 and the cloud.
- Downtime 23-25/04/2011
- Are you practising "safe surfing"?
- The Virtualbox bug: "Cannot access the kernel driver" in Windows
- Putting tech into perspective
2010
- Have a Google Buzz Christmas
- Root a G1 running Android 1.6 without recovery!
- Windows 7 display issues on old Dell desktops
- Google added the Apps flexibility we've been waiting for!
- Part I: My 3 step program for moving to Google Apps
- Downloading torrents
- Completing the Buzz experience for Google Maps Mobile
- Quicktip: Trial Google Apps
- Quicktip: Save internet images fast
- Turn your desktop 3D!
- Part III - Device not compatible - Skype on 3
- Swype not compatible? ShapeWriter!
- Don't wait, get Swype now!
- HideIP VPN. Finally!
- Google enables Wave for Apps domains
- Aspire One touch screen
- Streamline XP into Ubuntu
- Edit a PDF with Zamzar
- Google offering Gmail addresses in the UK
- Google Wave: Revolutionising blogs!
- Hexxeh's Google Chrome OS builds
- Update: Buzz on Windows Mobile
- Alternatives to Internet Explorer
- Wordress 3.0 is coming!
- Skype for WM alternatives
- Browsing on a (data) budget? Opera!
- Buzz on unsupported mobiles
- Buzz on your desktop
- What's all the Buzz?
- Part II: Device not compatible - Skype on 3
- Part I - Device not compatible - Skype on 3
- Dreamscene on Windows 7
- Free Skype with 3? There's a catch..
Change log
Experimenting with clustering and data replication in Nextcloud with MariaDB Galera and SyncThing
Contents
Update
#After discussions with the Nextcloud team and guys at TU Berlin, the below could be officially supported with some small changes. See the updates noted against the challenges. A rewrite or additional post will be coming soon to address and test the changes.
Nextcloud works really well as a standalone, single-server deployment. They additionally have some great recommendations for larger deployments supporting thousands of users and terabytes of data:
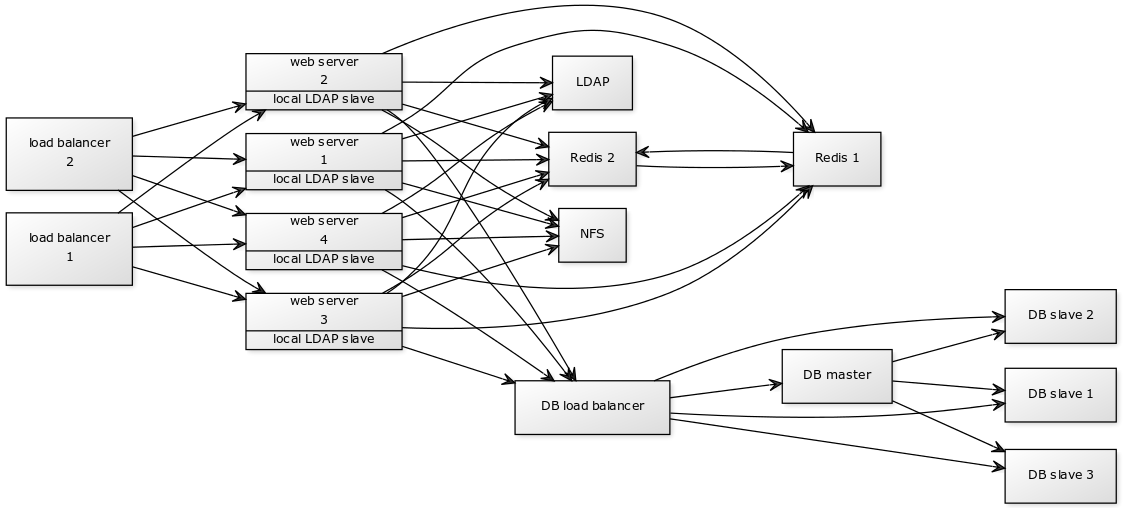 Up to 100,000 users and 1PB of data
Up to 100,000 users and 1PB of data
What wasn’t so apparent until last week, however, is how someone might deploy Nextcloud across multiple datacentres (or locations) in a distributed manner wherein each Node can act as the “master” at any point in time; federation is obviously a big feature in Nextcloud and works very well for connecting systems and building a trusted network of nodes, but that doesn’t do an awful lot for those wanting the type of enterprise deployment pictured above, without having all of the infrastructure on one network.
Now that Global Scale has been announced this will likely be the way forward when it’s ready, however given I’d already started a proof of concept (PoC) before NC12 was officially made available, I kept working away at it regardless – more for my own amusement than anything else for reasons explained further down.
The concept
#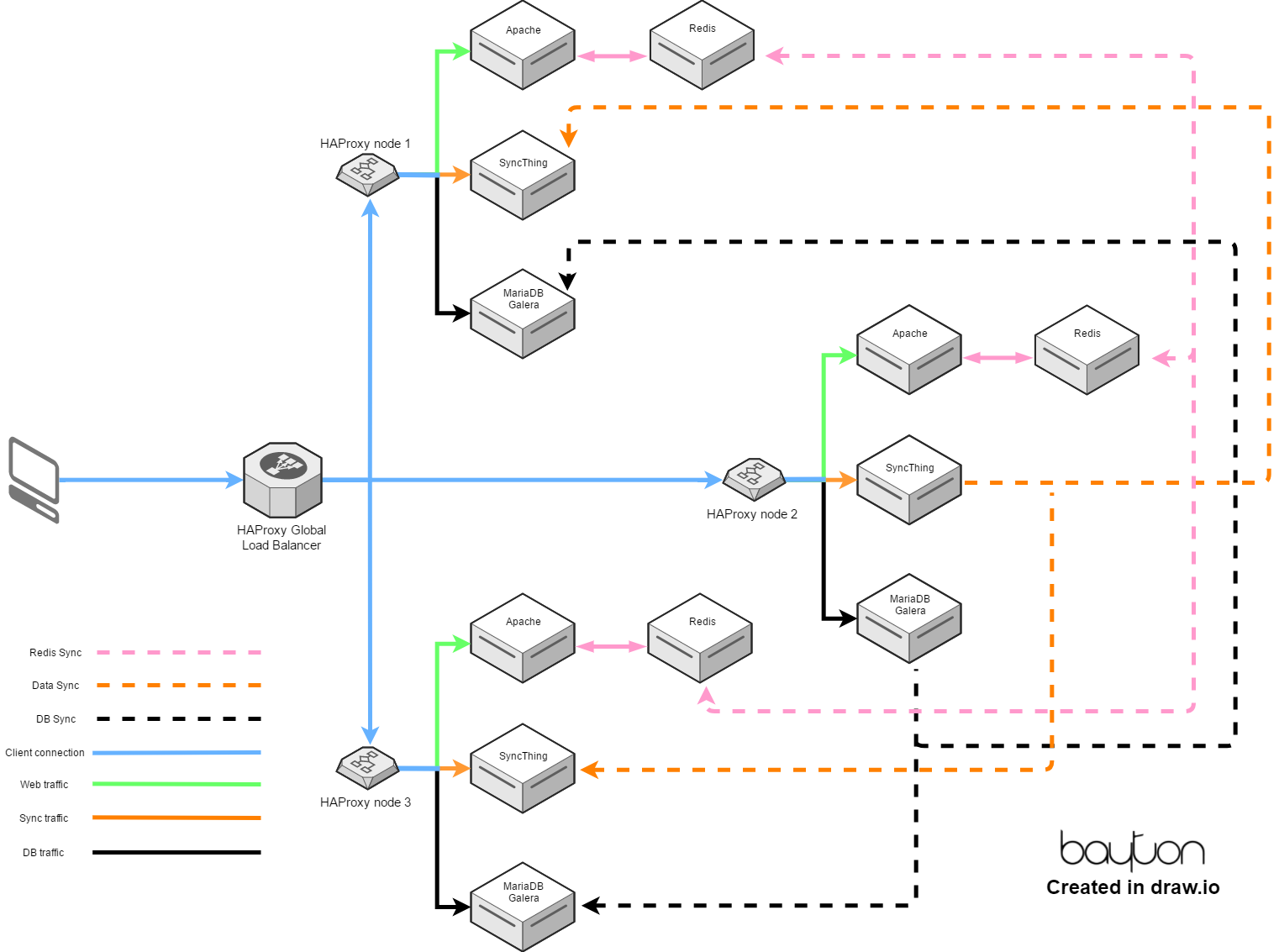
The theory was as follows:
If I’m at home, the server in the office is the best place to connect to since it’s on the LAN and performance will be excellent. In this case, a DNS override will point the FQDN for the Global Load Balancer (GLB) to a local HAProxy server that in turn points to the LAN Nextcloud instance unless it’s down, where the local HAProxy will divert to the GLB as normal.
If I leave the house and want to access my files, I’ll browse to the FQDN of the Nextcloud cluster (which points to the GLB) and the GLB will then forward my request seamlessly to the Nextcloud instance that responds the fastest.
In the graphic above, I opted for a future-proof infrastructure design that would:
- Only expose HAProxy to the internet directly, leaving the individual servers on the VLAN hidden out of the way
- Allow for expansion at any remote location by adding another server and populating it in the local HAProxy configuration
- Separate the webroot from the Apache server by mounting it via NFS from the SyncThing server, allowing for super quick provisioning of new Apache servers as required, writing back to the same dataset in one location.
- Sync session data to all nodes, so if I jumped from one node to the other due to latency, downtime or anything else, the other node(s) would allow me to continue without any noticeable delay.
No matter which Nextcloud instance I eventually land on, I wanted to be able to add/remove/edit files as normal and have all other instances sync the changes immediately. Further still, I wanted all nodes to be identical, that is if any file changes in the Nextcloud web directory on the server, it should be synced.
Why SyncThing?
#The answer to that is pretty much “why not?”. This isn’t a serious implementation and I had no intention of scaling the solution beyond this PoC. GlusterFS or any one of the alternative distributed filesystems are designed for what I’m doing here, but I wanted to get some hands-on time with SyncThing and didn’t see a reason I couldn’t implement it in this fashion. I talk about it more here with Resilio Sync, but swapped Resilio with SyncThing as Resilio is proprietary.
Challenges
#All recommended deployments suggest using Galera (MySQL or MariaDB) in a Master-Slave (-Slave-Slave, etc) configuration with a single centralised Master for writes and distributed slaves for quick reads. In my case, that could mean having a Master in Wales for which the nodes in France, Holland, Finland, Canada or anywhere else would have to connect to in order to write, introducing latency.
To get around this, I opted for Galera Master-Master. This setup isn’t supported by Nextcloud I later found out (by reading the docs, no less, oops) but at the time it appeared to work fine – I uploaded 10,000 files in reasonably quick succession with no database or Nextcloud errors reported, however that may well have simply been luck.
Update: Galera Master-Master is supported, however a load-balancer supporting split read/write must be used in front of it. The master should be persistent and only failover to another Galera server in case of failure. ProxySQL (https://www.proxysql.com/) offers this functionality and is FOSS.
At a minimum I’d have to replicate apps, themes and data for the individual nodes to sync data and retain a consistent user experience; enabling an app on one node wouldn’t be automatically enabled on the other node otherwise, as it’d first need to be downloaded from the Nextcloud store. I didn’t want to think of the issues this would cause for the database.
At this point I also considered the impact of upgrades, as when one Nextcloud instance successfully upgrades and makes changes to the database, the other nodes will want to do the same as part of the upgrade process. So rather than just syncing the data, apps and themes folders individually, I opted to replicate the entire /nextcloud webroot folder between nodes on a 5-second sync schedule (that is, there will be a maximum of 5 sec before data uploaded to one node is replicated to the others).
In testing this setup in several containers on the home server, the additional load this put on the machine was enormous during an upgrade of Nextcloud; a hex-core with 32GB RAM and SSD-backed storage ended up with a load average nearing 30, far more than the normal 0.4 it typically runs at; not so much a problem with a distributed service but where traffic is monitored with some providers, the constant sync could have an impact on transfer caps.
Load and data transfer aside, the tests were successful; I updated Nextcloud from 11.0.3 to 12.0.0 and watched it almost immediately start replicating the changing data as the upgrade took place – it was beautiful.
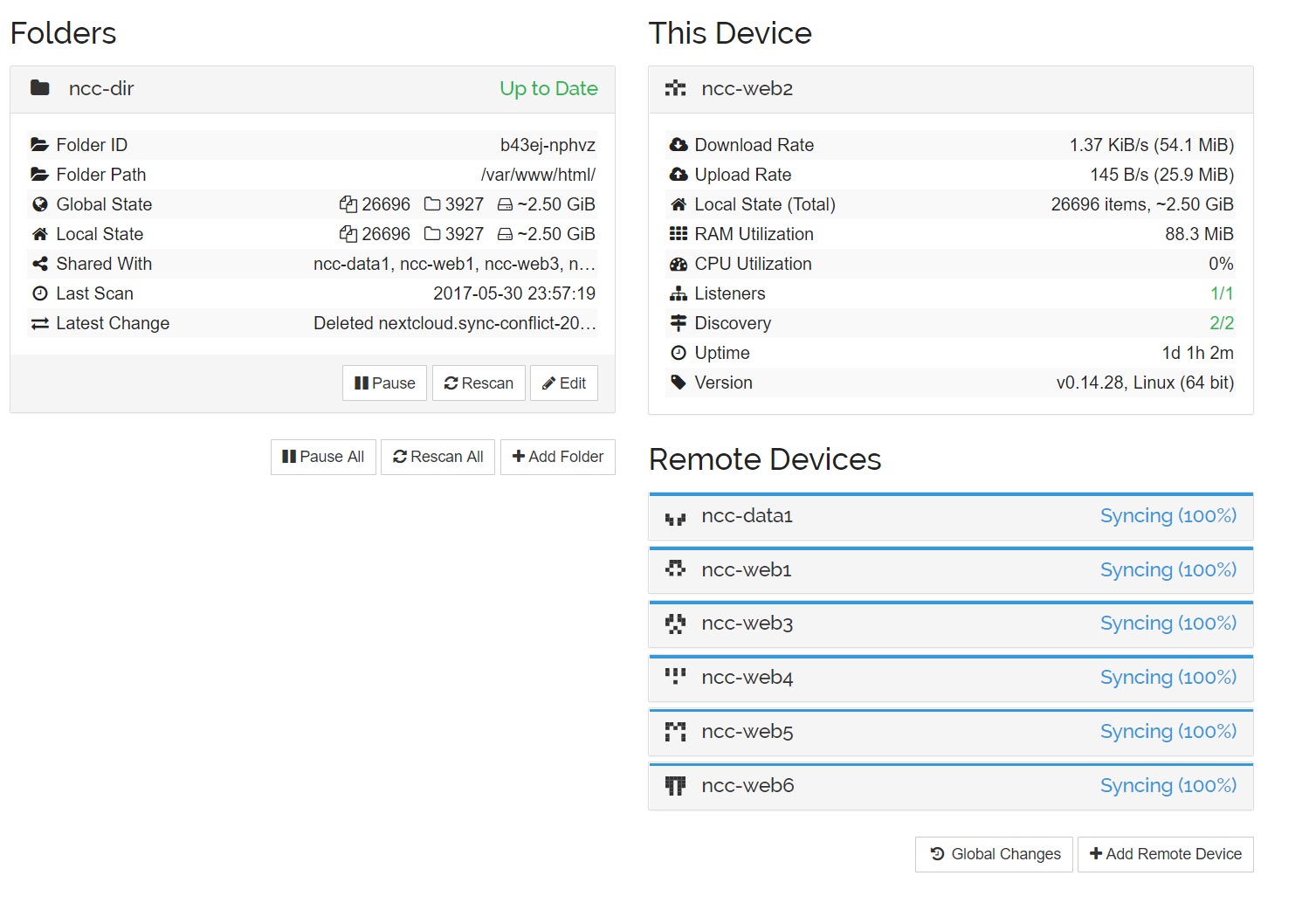
This was naturally the 2nd attempt, as first I’d forgotten to leave the Nextcloud service in maintenance mode until all sync had ceased, and on accessing one of the nodes before it had completed, things started going wrong and the nodes fell out of sync. Keeping maintenance mode enabled until it was 100% synced across all nodes then worked every attempt (where an attempt involved restoring the database and falling back to snapshots from 11.0.3).
Update: SyncThing is a nice PoC, but if you’re seriously planning to run a distributed setup I’d strongly recommend Gluster or another distributed storage solution.
HAProxy wasn’t failing over fast enough. If a node went down (Apache stopped, MySQL stopped or server shut down) and the page refreshed anywhere up to 2-3 seconds later HAProxy may not have downed the node quite yet and throws an error.
Getting past that didn’t take long fortunately, and I ended up making the following changes to the HAProxy config:
server web1 10.10.20.1:80 <strong>check fall 1 rise 2</strong>
This tells HAProxy to check the servers in its configuration, but more importantly drop them out of circulation after only one failure to connect when doing a check, and require two successful checks to bring a server back in. After this it was much faster and knowing I had enough nodes to handle this type of configuration I wasn’t concerned about HAProxy potentially dropping a few of them out in quick succession if required.
Redis doesn’t really do clustering, and authentication options are limited.
This was pretty much a stopper for distributed session storage. Redis docs and a lot of Googling led me to the conclusion I can’t cluster Redis. Therefore each node would have to report session information on all Redis nodes. That’s not a dealbreaker, but worse, either Redis remains completely open on the internet for the nodes to connect to, or if authentication is used, it’s sent in plaintext. Not good. Redis suggests connecting in via VPN or tunneling, but that feels like it defeats the purpose of this exercise and requires a lot more configuration. Perhaps Memcached could solve the problem, or figuring out a way of replicating the session files with plain-old PHP session handling. I didn’t look much further into it.
Update: Speaking to TUBerlin, they got around this with IP-whitelisting between Redis nodes. Ultimately Redis can be left “open” and without authentication, however on the server/network level, only whitelisted IPs may successfully communicate with the Redis nodes. Within the Nextcloud configuration, stipulating all Redis nodes is the only way of achieving replication (as Nextcloud will write to them all).
SyncThing comes with user-based Systemd service files, and after a while of trying to make them succumb to my will for a custom user and home directory (because the web user doesn’t always have a “home“, despite pointing to /var/www/ SyncThing kept dying on me when I’d made the changes)
Being all data is presented, manipulated and used by www-data for Nextcloud, I needed to ensure SyncThing ran as www-data in order to retain permissions and not run into issues trying to manage data in a non-user directory (/var/www/html/nextcloud/data). Because of this, I edited the default SyncThing service files to create some that aren’t user-based with a custom home directory, as follows:
Syncthing Service
Syncthing-inotify Service
Testing
#So in order to confirm it was all working as it should be I did the following:
- Increased the web nodes from 3 to 6 to test data replication. Piece of cake in the home environment as it was just a case of cloning an existing LXD apache node and assigning a new IP address. However I additionally spun up some blank Ubuntu containers and configured from scratch, this included:
- PHP settings for max upload, max post size, etc
- Apache settings for htaccess overrides and a conf file for default webroot location with Nextcloud (
/var/www/html/nextcloud) - Mounting SyncThing repo via NFS
- Static IP, updates, general server maintenance
- Initiated a load test via Load Impact against the FQDN and monitored the HAProxy logs, brief video below
- Manually downed both Galera nodes and web nodes, then brought them back up to test HAProxy failover
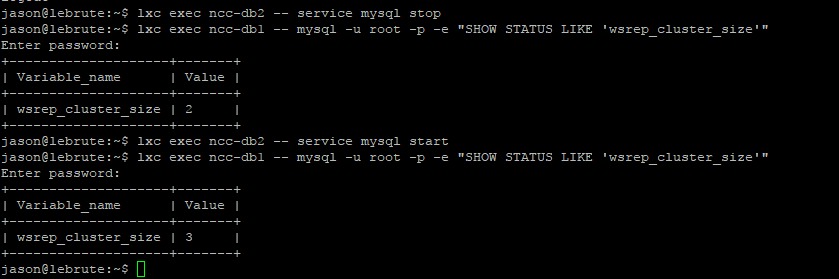 Here I dropped a Galera node, checked the state of Galera, brought it back in and checked again. Exciting.
Here I dropped a Galera node, checked the state of Galera, brought it back in and checked again. Exciting.
And here’s a snippet of the load test at work on HAProxy (web nodes only):
I don’t know why I recorded that rather than screen capture, but c’est la vie.
During the load test Nextcloud remained responsive, load on the server went off the charts but that was fine as it too remained responsive. I could continue to upload, edit, download and use Nextcloud, so I was happy with it.
The next step would have been to start replicating the home server setup on remote servers, I’d considered a couple of containers with ElasticHosts, one or two LightSail servers from Amazon and perhaps a VPS with OVH. However this didn’t happen due to at this point finding out Galera isn’t supported, and Redis was going to cause me problems.
What I learned
#In conclusion, this type of deployment for Nextcloud seems to work, but isn’t feasible. Redis is a bit of a stopper and an alternative would need to be found, and Galera master-master is a major issue and a bit of an inconvenience in master-slave. Here’re the details I published over on the Nextcloud forums:
- SyncThing is super reliable, handles thousands upon thousands of files and has the flexibility to be used in a usecase such as this; full webapp replication between several servers without any fuss however:
- Feasibility in a distributed deployment model where latency and potentially flaky connections wasn’t tested thoroughly, and while the version management was spot on at picking up on out of sync files, it would need far more testing before being even remotely considered for a larger deployment
- Load on the server can be excessive if left setup in a default state, however intentionally reducing the cap for the processes will obviously impact sync speed and reliability
- Data/app replication between sites is not enough if you have multiple nodes sharing a single database
- The first few attempts at a NC upgrade for example led to issues with every other node once the first had a) updated itself and b) made changes to the database.
- This may be rectified by undertaking upgrades on each node individually but stopping at the DB step, opting to only run that on the one, I didn’t test this though.
- I think a common assumption is you only need to replicate
/data, however what happens if an admin adds an app on one node? It doesn’t show up on the others. Same for themes.
- The first few attempts at a NC upgrade for example led to issues with every other node once the first had a) updated itself and b) made changes to the database.
- Galera is incredible
- The way it instantly replicates, fails over and recovers, particularly combined with HAProxy which can instantly see when a DB is down and divert, is so silky smooth I couldn’t believe it.
- Although a powercut entirely wiped Galera out and I had to build it again, this wouldn’t happen in a distributed scenario.. despite the cluster failure I was still able to extract the database and start again with little fuss anyway.
- The master-master configuration is not compatible with NC, so at best you’ll have a master-slave(n) configuration, where all nodes have to write to the one master no matter where in the world it might be located. Another solution for multimaster is needed in order for nodes to be able to work seamlessly as if they’re the primary at all times.
- Remote session storage is a thing, and NC needs it if using multiple nodes behind a floating FQDN
- Otherwise refreshing the page could take you to another node and your session would be nonexistent. Redis was a piece of cake to setup on a dedicated node (though it could also live on an existing node) and handled the sessions fine in the home environment.
- It doesn’t seem to scale well though, with documentation suggesting VPN or tunneling to gain access to each Redis node in a Redis “cluster” (not a real cluster) as authentication is plaintext or nothing, and that’s bad if you’re considering publishing it to the internet for nodes to connect to.
- When working with multiple nodes, timing is everything.
- I undertook upgrades that synced across all nodes without any further input past kicking it off on the first node; however don’t ever expect to be able to take the node out of maintenance mode in a full-sync environment until all nodes have successfully synced, otherwise some nodes will sit in a broken state until complete
- Upgrading/installing apps/other sync related stuff takes quite a bit longer, but status pages of SyncThing or another distributed storage/sync solution will keep you updated on sync progress
- The failover game must be strong
Conclusion
#With the Redis exception I basically built an unsupported, but successful, distributed Nextcloud solution that synced well, maintained high availability at all times and only really suffered the odd discrepancy due to session storage not working properly.
SyncThing proved its worth to me, so I’ll definitely be looking more into that at some point soon. In the meantime, this experiment is over and all servers have been shut down:
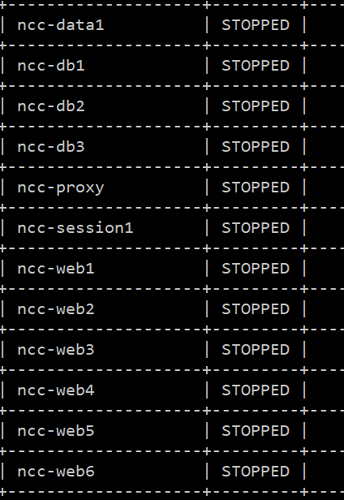
If you have suggestions for another master-master database solution that could work*, and a session storage option that will either a) cluster or b) support authentication that isn’t completely plaintext, let me know!
*Keep in mind:
A multi-master setup with Galera cluster is not supported, because we require
READ-COMMITTEDas transaction isolation level. Galera doesn’t support this with a master-master replication which will lead to deadlocks during uploads of multiple files into one directory for example.
Have you attempted this kind of implementation with Nextcloud? Do you have any tips? Were you more or less successful than my attempt? Let me know in the comments, @jasonbayton on twitter or @bayton.org on Facebook.
Articles
2026
- What the last decade of Android Enterprise DPC migration could have been
- Introducing DeltaWatch: web change detection
- Android Enterprise lands on Android XR
- How MIKA works: building an AI assistant for bayton.org
- Bayton.org goes AI-first: meet MIKA
- TCL Note A1 NXTPAPER hands-on
- What's new in the 2026 Android Security Paper?
- MDM is dead. Long live ACE?
- Introducing AMAPI Commander: converse with your Android estate
- MANAGED INFO is going licence-free
2025
- Google Play Protect is now the custom DPC gatekeeper, and everyone is a threat by default
- 12 deliveries of AE-mas (What shipped in Android Enterprise in 2025)
- The 12 AE requests of Christmas (2025 Edition)
- RCS Archival and you: clearing up the misconceptions
- Device Trust from Android Enterprise: What it is and how it works (hands-on)
- Android developer verification: what this means for consumers and enterprise
- AMAPI finally supports direct APK installation, this is how it works
- The Android Management API doesn't support pulling managed properties (config) from app tracks. Here's how to work around it
- Hands-on with CVE-2025-22442, a work profile sideloading vulnerability affecting most Android devices today
- AAB support for private apps in the managed Google Play iFrame is coming, take a first look here
- What's new (so far) for enterprise in Android 16
2024
- Android 15: What's new for enterprise?
- How Goto's acquisition of Miradore is eroding a once-promising MDM solution
- Google Play Protect no longer sends sideloaded applications for scanning on enterprise-managed devices
- Mobile Pros is moving to Discord
- Avoid another CrowdStrike takedown: Two approaches to replacing Windows
- Introducing MANAGED SETTINGS
- I'm joining NinjaOne
- Samsung announces Knox SDK restrictions for Android 15
- What's new (so far) for enterprise in Android 15
- Google quietly introduces new quotas for unvalidated AMAPI use
- What is Play Auto Install (PAI) in Android and how does it work?
- AMAPI publicly adds support for DPC migration
- How do Android devices become certified?
2023
- Mute @channel & @here notifications in Slack
- A guide to raising better support requests
- Ask Jason: How should we manage security and/or OS updates for our devices?
- Pixel 8 series launches with 7 years of software support
- Android's work profile behaviour has been reverted in 14 beta 5.3
- Fairphone raises the bar with commitment to Android updates
- Product files: The DoorDash T8
- Android's work profile gets a major upgrade in 14
- Google's inactive account policy may not impact Android Enterprise customers
- Product files: Alternative form factors and power solutions
- What's new in Android 14 for enterprise
- Introducing Micro Mobility
- Android Enterprise: A refresher
2022
- What I'd like to see from Android Enterprise in 2023
- Thoughts on Android 12's password complexity changes
- Google Play target API requirements & impact on enterprise applications
- Sunsetting Discuss comment platform
- Google publishes differences between Android and Android Go
- Android Go & EMM support
- Relaunching bayton.org
- AER dropped the 3/5 year update mandate with Android 11, where are we now?
- I made a bet with Google (and lost)
2020
- Product files: Building Android devices
- Google announce big changes to zero-touch
- VMware announces end of support for Device Admin
- Google launch the Android Enterprise Help Community
- Watch: An Android Enterprise discussion with Hypergate
- Listen again: BM podcast #144 - Jason Bayton & Russ Mohr talk Android!
- Google's Android Management API will soon support COPE
- Android Enterprise in 11: Google reduces visibility and control with COPE to bolster privacy.
- The decade that redefined Android in the enterprise
2019
- Why Intune doesn't support Android Enterprise COPE
- VMware WS1 UEM 1908 supports Android Enterprise enrolments on closed networks and AOSP devices
- The Bayton 2019 Android Enterprise experience survey
- Android Enterprise Partner Summit 2019 highlights
- The Huawei ban and Enterprise: what now?
- Dabbling with Android Enterprise in Q beta 3
- Why I moved from Google WiFi to Netgear Orbi
- I'm joining Social Mobile as Director of Android Innovation
- Android Enterprise in Q/10: features and clarity on DA deprecation
- MWC 2019: Mid-range devices excel, 5G everything, form-factors galore and Android Enterprise
- UEM tools managing Android-powered cars
- Joining the Android Enterprise Experts community
- February was an interesting month for OEMConfig
- Google launch Android Enterprise Recommended for Managed Service Providers
- Migrating from Windows 10 Mobile? Here's why you should consider Android
- AER expands: Android Enterprise Recommended for EMMs
- What I'd like to see from Android Enterprise in 2019
2018
- My top Android apps in 2018
- Year in review: 2018
- MobileIron Cloud R58 supports Android Enterprise fully managed devices with work profiles
- Hands on with the Huawei Mate 20 Pro
- Workspace ONE UEM 1810 introduces support for Android Enterprise fully managed devices with work profiles
- G Suite no longer prevents Android data leakage by default
- Live: Huawei Mate series launch
- How to sideload the Digital Wellbeing beta on Pie
- How to manually update the Nokia 7 Plus to Android Pie
- Hands on with the BQ Aquaris X2 Pro
- Hands on with Sony OEMConfig
- The state of Android Enterprise in 2018
- BYOD & Privacy: Don’t settle for legacy Android management in 2018
- Connecting two Synologies via SSH using public and private key authentication
- How to update Rsync on Mac OS Mojave and High Sierra
- Intune gains support for Android Enterprise COSU deployments
- Android Enterprise Recommended: HMD Global launch the Nokia 3.1 and Nokia 5.1
- Android Enterprise Partner Summit 2018 highlights
- Live: MobileIron LIVE! 2018
- Android Enterprise first: AirWatch 9.4 lands with a new name and focus
- Live: Android Enterprise Partner Summit 2018
- Samsung, Oreo and an inconsistent Android Enterprise UX
- MobileIron launch Android Enterprise work profiles on fully managed devices
- Android P demonstrates Google's focus on the enterprise
- An introduction to managed Google Play
- MWC 2018: Android One, Oreo Go, Android Enterprise Recommended & Android Enterprise
- Enterprise ready: Google launch Android Enterprise Recommended
2017
- Year in review: 2017
- Google is deprecating device admin in favour of Android Enterprise
- Hands on with the Sony Xperia XZ1 Compact
- Moto C Plus giveaway
- The state of Android Enterprise in 2017
- Samsung launched a Note 8 for enterprise
- MobileIron officially supports Android Enterprise QR code provisioning
- Android zero-touch enrolment has landed
- MobileIron unofficially supports QR provisioning for Android Enterprise work-managed devices, this is how I found it
- Hands on with the Nokia 3
- Experimenting with clustering and data replication in Nextcloud with MariaDB Galera and SyncThing
- Introducing documentation on bayton.org
- Goodbye Alexa, Hey Google: Hands on with the Google Home
- Restricting access to Exchange ActiveSync
- What is Mobile Device Management?
- 8 tips for a successful EMM deployment
- Long-term update: the fitlet-RM, a fanless industrial mini PC by Compulab
- First look: the FreedomPop V7
- Vault7 and the CIA: This is why we need EMM
- What is Android Enterprise (Android for Work) and why is it used?
- Introducing night mode on bayton.org
- What is iOS Supervision and why is it used?
- Hands on with the Galaxy TabPro S
- Introducing Nextcloud demo servers
- Part 4 - Project Obsidian: Obsidian is dead, long live Obsidian
2016
- My top Android apps 2016
- Hands on with the Linx 12V64
- Wandera review 2016: 2 years on
- Deploying MobileIron 9.1+ on KVM
- Hands on with the Nextcloud Box
- How a promoted tweet landed me on Finnish national news
- Using RWG Mobile for simple, cross-device centralised voicemail
- Part 3 – Project Obsidian: A change, data migration day 1 and build day 2
- Hands on: fitlet-RM, a fanless industrial mini PC by Compulab
- Part 2 - Project Obsidian: Build day 1
- Part 1 - Project Obsidian: Objectives & parts list
- Part 0 - Project Obsidian: Low power NAS & container server
- 5 Android apps improving my Chromebook experience
- First look: Android apps on ChromeOS
- Competition: Win 3 months of free VPS/Container hosting - Closed!
- ElasticHosts review
- ElasticHosts: Cloud Storage vs Folders, what's the difference?
- Adding bash completion to LXD
- Android N: First look & hands-on
- Springs.io - Container hosting at container prices
- Apple vs the FBI: This is why we need MDM
- Miradore Online MDM: Expanding management with subscriptions
- Lenovo Yoga 300 (11IBY) hard drive upgrade
- I bought a Lenovo Yoga 300, this is why I'm sending it back
- Restricting access to Exchange ActiveSync
- Switching to HTTPS on WordPress
2015
2014
- Is CYOD the answer to the BYOD headache?
- BYOD Management: Yes, we can wipe your phone
- A fortnight with Android Wear: LG G Watch review
- First look: Miradore Online free MDM
- Hands on: A weekend with Google Glass
- A month with Wandera Mobile Gateway
- Final thoughts: Dell Venue Pro 11 (Atom)
- Thoughts on BYOD
- Will 2014 bring better battery life?
- My year in review: Bayton.org
- The best purchase I've ever made? A Moto G for my father
2013
2012
- My Top Android Apps 12/12
- The Nexus 7 saga: Resolved
- Recycling Caps Lock into something useful - Ubuntu (12.04)
- The Nexus 7 saga continues
- From Wows to Woes: Why I won't be recommending a Nexus7 any time soon.
- Nexus7: What you need to know
- Why I disabled dlvr.it links on Facebook
- HTC Sense: Changing the lockscreen icons from within ADW
2011
- Push your Google+ posts to Twitter and Facebook
- Using multiple accounts with Google.
- The "Wn-R48" (Windows on the Cr-48)
- Want a Google+ invite?
- Publishing to external sources from Google+
- Dell Streak review. The Phone/Tablet Hybrid
- BlueInput: The Bluetooth HID driver Google forgot to include
- Pushing Buzz to Twitter with dlvr.it
- Managing your social outreach with dlvr.it
- When Awe met Some. The Cr-48 and Gnome3.
- Living with Google's Cr-48 and the cloud.
- Downtime 23-25/04/2011
- Are you practising "safe surfing"?
- The Virtualbox bug: "Cannot access the kernel driver" in Windows
- Putting tech into perspective
2010
- Have a Google Buzz Christmas
- Root a G1 running Android 1.6 without recovery!
- Windows 7 display issues on old Dell desktops
- Google added the Apps flexibility we've been waiting for!
- Part I: My 3 step program for moving to Google Apps
- Downloading torrents
- Completing the Buzz experience for Google Maps Mobile
- Quicktip: Trial Google Apps
- Quicktip: Save internet images fast
- Turn your desktop 3D!
- Part III - Device not compatible - Skype on 3
- Swype not compatible? ShapeWriter!
- Don't wait, get Swype now!
- HideIP VPN. Finally!
- Google enables Wave for Apps domains
- Aspire One touch screen
- Streamline XP into Ubuntu
- Edit a PDF with Zamzar
- Google offering Gmail addresses in the UK
- Google Wave: Revolutionising blogs!
- Hexxeh's Google Chrome OS builds
- Update: Buzz on Windows Mobile
- Alternatives to Internet Explorer
- Wordress 3.0 is coming!
- Skype for WM alternatives
- Browsing on a (data) budget? Opera!
- Buzz on unsupported mobiles
- Buzz on your desktop
- What's all the Buzz?
- Part II: Device not compatible - Skype on 3
- Part I - Device not compatible - Skype on 3
- Dreamscene on Windows 7
- Free Skype with 3? There's a catch..